IT运维分析与海量日志搜索需要注意什么(1)
2016-02-20 19:34:15 来源: 陈军 互联网运维杂谈 评论:0 点击:
IT运维分析,即IT Operation Analytics,简称ITOA,是个新名词。以前IT运维是ITOM,IT Operation Management ,IT 运维管理。这两年大数据技术开始普及,把大数据技术应用于IT运维,通过数据分析提升IT运维效率与水平,就是ITOA。本文是日志易创始人兼CEO陈军老师一次主题为“IT运维分析与海量日志搜索 ”的线上分享。

日志易创始人兼CEO陈军老师12月16日在【DBA+社群】中间件用户组进行了一次主题为“IT运维分析与海量日志搜索 ”的线上分享。
目录:
◆IT 运维分析(IT Operation Analytics)
◆日志的应用场景
◆过去及现在的做法
◆日志搜索引擎
◆日志易产品介绍
一、IT 运维分析
1、IT 运维分析
1.1 从 IT Operation Management (ITOM) 到 IT Operation Analytics (ITOA)
IT运维分析,即IT Operation Analytics,简称ITOA,是个新名词。以前IT运维是ITOM,IT Operation Management ,IT 运维管理。这两年大数据技术开始普及,把大数据技术应用于IT运维,通过数据分析提升IT运维效率与水平,就是ITOA。
1.2 大数据技术应用于IT运维,通过数据分析提升IT运维
ITOA主要用于:
◆可用性监控
◆应用性能监控
◆故障根源分析
◆安全审计
1.3 Gartner估计,到2017年15%的大企业会积极使用ITOA;而在2014年这一数字只有5%。
2、ITOA的数据来源有以下四个方面:
1.1 机器数据(Machine Data):是IT系统自己产生的数据,包括客户端、服务器、网络设备、安全设备、应用程序、传感器产生的日志,及 SNMP、WMI 等时间序列事件数据,这些数据都带有时间戳。机器数据无所不在,反映了IT系统内在的真实状况,但不同系统产生的机器数据的质量、可用性、完整性可能差别较大。
1.2 通信数据(Wire Data):是系统之间2~7层网络通信协议的数据,可通过网络端口镜像流量,进行深度包检测 DPI(Deep Packet Inspection)、包头取样 Netflow 等技术分析。一个10Gbps端口一天产生的数据可达100TB,包含的信息非常多,但一些性能、安全、业务分析的数据未必通过网络传输,一些事件的发生也未被触发网络通信,从而无法获得。
1.3 代理数据(Agent Data):是在 .NET、PHP、Java 字节码里插入代理程序,从字节码里统计函数调用、堆栈使用等信息,从而进行代码级别的监控。但要求改变代码并且会增加程序执行的开销,降低性能,而且修改了用户的程序也会带来安全和可靠性的风险。
1.4 探针数据(Probe Data),又叫合成数据(Synthetic Data):是模拟用户请求,对系统进行检测获得的数据,如 ICMP ping、HTTP GET等,能够从不同地点模拟客户端发起,进行包括网络和服务器的端到端全路径检测,及时发现问题。但这种检测并不能发现系统为什么性能下降或者出错,而且这种检测是基于取样,并不是真实用户度量(Real User Measurement)。
拥有大量客户端的公司,如BAT,会直接在客户端度量系统性能,做Real User Measurement,通常不需要模拟用户检测。
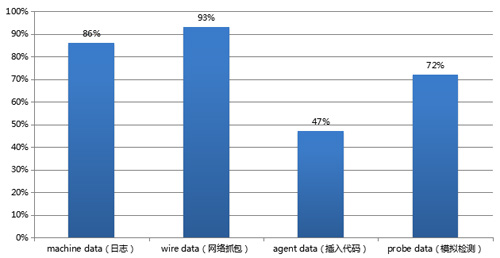
3、ITOA 四种数据来源使用占比
美国某ITOA公司的用户调研发现,使用这四种不同数据来源的比例为:Machine Data 86%, Wire Data 93%, Agent Data 47%, Probe Data 72%。这四种数据来源各有利弊,结合在一起使用,效果最好。
4、日志:时间序列机器数据
通常结合日志与网络抓包,能够覆盖大部分IT运维分析的需求。日志因为带有时间戳,并由机器产生,也被称为时间序列机器数据。
它包含了IT系统信息、用户信息、业务信息。
日志反映的是事实数据:LinkedIn(领英)是非常著名的职业社交应用,非常重视用户数据分析,也非常重视日志。
它的一个工程师写了篇很有名的文章:
◆“The Log: What every software engineer should know about real-time data's unifying abstraction”, Jay Kreps, LinkedIn engineer
附:中文翻译:深度解析LinkedIn大数据平台
LinkedIn的用户数据挖掘基于日志,公司内部有专门的部门处理所有的日志,各模块的日志都被采集,传送到这个部门。
著名的开源消息队列软件Kafka就是LinkedIn开发,用来传输日志的。
以Apache日志为例,包含了非常丰富的信息:
- 180.150.189.243 - - [15/Apr/2015:00:27:19 +0800] “POST /report HTTP/1.1” 200 21 “https://rizhiyi.com/search/” “Mozilla/5.0 (Windows NT 6.1; WOW64; rv:37.0) Gecko/20100101 Firefox/37.0” “10.10.33.174” 0.005 0.001
里面包含的字段:
- Client IP: 180.150.189.243
- Timestamp: 15/Apr/2015:00:27:19 +0800
- Method: POST
- URI: /report
- Version: HTTP/1.1
- Status: 200
- Bytes: 21
- Referrer: https://rizhiyi.com/search/
- User Agent: Mozilla/5.0 (Windows NT 6.1; WOW64; rv:37.0) Gecko/20100101 Firefox/37.0
- X-Forward: 10.10.33.174
- Request_time: 0.005
- Upstream_request_time:0.001
可见,日志是非结构化文本数据,如果分析,最好把它转换为结构化数据。
上面就是抽取了各个字段,把日志结构化了,结构化之后,统计、分析就很方便了。
二、日志的应用场景
1、运维监控
包括可用性监控和应用性能监控 (APM)。
2、安全审计
包括安全信息事件管理 (SIEM)、合规审计、发现高级持续威胁 (APT)。
3、用户及业务统计分析
上一篇:优秀的运维架构师应该具备哪些能力?(1)
下一篇:49款顶级开源办公工具推荐(1)
分享到:
 收藏
收藏
收藏
